(通讯员黄永)我院2021级博士研究生姜艺以第一作者身份撰写的论文被信息科学领域顶级期刊国际信息科学与技术学会会刊(Journal of the Association for Information Science and Technology,JASIST)录用。论文题目为“Generating Keyphrases for Readers: A Controllable Keyphrase Generation Framework”,指导教师和通讯作者为我院院长、信息检索与知识挖掘研究所所长陆伟教授。

随着关键词在信息检索与自然语言处理任务中的广泛应用,关键词抽取逐渐兴起。然而,由于深度学习的端到端学习机制,使模型能够直接学习文本的重要语义信息,在统计层面上重要的关键词对相关任务的贡献越来越小。同样,由于大多数论文的关键词几乎都没有明确标注其与论文内容的对应关系,这使得读者无法像作者一样清晰地知道各个关键词在特定上下文中的语义角色,即关键词功能。相对作者而言,读者所见的关键词语义并不完整(如下图所示),仅根据关键词文本本身难以快速理解文章的主要内容。在某种程度上,关键词似乎不够重要,关键词抽取的必要性也有待商榷。
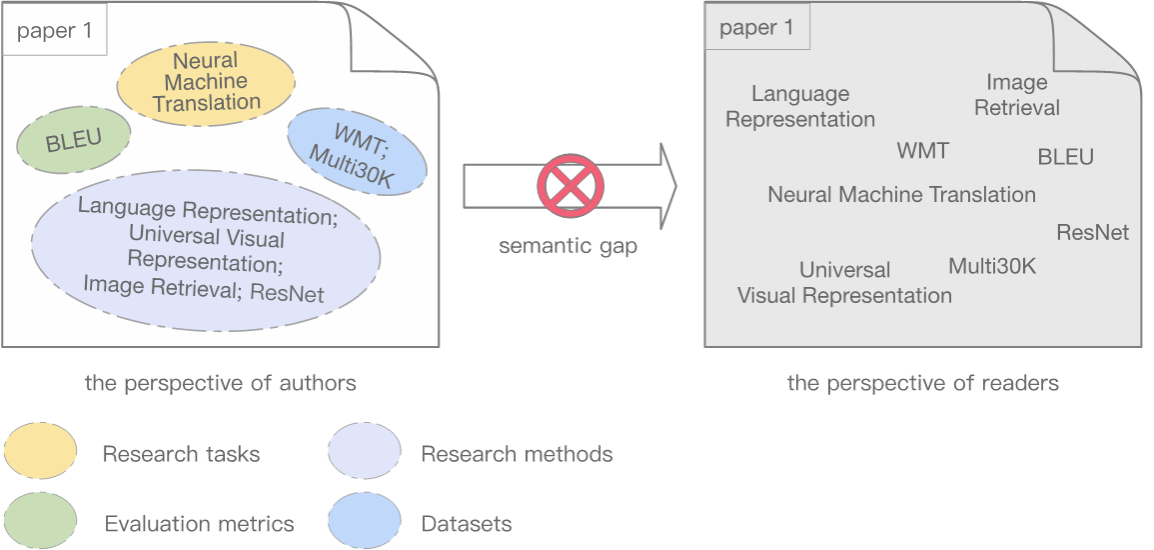
不同于关键词,实体的类别明确界定了其所属的知识范畴,极大地规避了语义缺失问题。同时,有研究指出,明确论文中特定类别的重要概念,将有助于快速回答研究工作的主要内容,比如“本文提出或改进了某方法,解决了某问题”。受此启发,该研究尝试为关键词标注功能类别,以完善关键词的语义信息,使其在辅助读者快速了解论文核心内容方面充分发挥作用。通过用户实验,验证了关键词功能对辅助读者快速理解论文主要内容的有效性。在此基础上,该研究重新审视了关键词自动抽取任务,提出生成特定语义功能的关键词,以弥合读者与论文作者在关键词理解层面的语义鸿沟,进而构建并实现了一个可控的关键词生成框架——CKPG (Controllable Keyphrase Generation framework)。
该研究分别基于Transformer、BART和T5实现了CKPG模型并取得了较好的实验效果,P@5、R@5和F1@5的宏平均值分别高达0.680、0.535和0.558。相关实验结果表明,CKPG模型能够生成语义边界清晰、功能类别分明的论文关键词。另外,论文对比了先抽取再分类的两阶段方法。假设第一阶段的关键词抽取准确率为100%,在第二阶段,基于词频、位置信息、文本相似度等5个特征训练了多个分类模型,对在文中出现的全部关键词进行功能分类。实验结果表明,在最大化两阶段方法抽取准确率的前提下,端到端的CKPG模型也更具优势,充分证明了该模型对于所提关键词生成任务的有效性。
论文链接:https://doi.org/10.1002/asi.24749
